
Multi-Touch Attribution (MTA): The Technical Guide to Data, Pipelines & Models
Everything you need to know to build durable pipelines, unify data, and choose the right models for trustworthy, executive-ready MTA.

Marketing today is in constant evolution. Once someone’s got their teeth in how it works, Google makes a change, AI makes a business-changing update, and everyone’s back in purgatory again. When your data is all over the place, it's especially challenging.
While multi-touch attribution (MTA) is widely understood as the answer, many organizations still struggle to implement it effectively.
Channels, CRMs, web analytics, and offline systems all tell different versions of the truth, so even the most innovative attribution model ends up sitting atop incomplete or conflicting data.
This guide is for teams who want to fix that at the root. We’ll walk through how to design the data infrastructure behind reliable MTA: unified identities, clean event streams, a central warehouse, and a pipeline that can actually support rule-based, probabilistic, and machine-learning models.
If you’re asking “Which attribution model should we use?” but haven’t fully answered “Can we trust the data feeding any model at all?”, this guide is the technical blueprint you need.
Likewise, if you’re just scratching the surface of multi-touch attribution, ease into the basics first, then refer back to this blueprint.
But First, Why Care About MTA?
Traditional first-touch and last-touch models assign 100% of conversion credit to a single interaction. MTA distributes credit across multiple touchpoints in the customer journey, giving you:
- A nuanced understanding of how campaigns work together
- Optimized budget allocation
- Better ROI
- A deeper view of the full funnel, from awareness through conversion
With the global MTA software market nearing $12B by 2032, it’s clear that attribution now sits at the center of serious marketing decision-making. Lacking it today is the difference between guessing through fog and seeing your funnel with true clarity.
The Foundational Building Blocks of Successful MTA
#1. Effective Data Integration
Most attribution conversations start with models. In reality, attribution accuracy is constrained long before modeling ever begins. The true limiter of MTA performance is data integrity.
If identities don’t resolve cleanly, timestamps don’t align, channels aren’t normalized, or events aren’t consistent, you’re not running attribution, you’re running assumptions at scale.
No attribution model can compensate for:
- Incomplete data ingestion
- Cross-platform identity fragmentation
- Broken sessionization
- Gaps in conversion tracking
Without a unified view of the customer journey, your MTA system is fundamentally blind. The model may look sophisticated on the surface, but it’s built on unstable inputs.
#2. Unified Data
Multi-touch attribution is fundamentally a data unification problem before it is ever a modeling problem. To assign accurate credit, you must see the complete chronological path a customer takes from first interaction through conversion and beyond.
That means:
- Stitching together web analytics, ad platforms, CRM, email, and offline data
- Aligning identifiers across tools (user IDs, emails, device IDs, etc.)
- Building one coherent narrative per user or account
A comprehensive MTA setup should consider:
- Digital Ads: Google Ads, Meta, LinkedIn, TikTok impressions and clicks
- Organic Channels: SEO, direct, organic social
- Email Marketing: Sends, opens, clicks, and key events
- CRM Data: Sales calls, demos, opportunities, pipeline stages
- Website Analytics: Page views, content engagement, form fills, product views
- Offline Events: In-store visits, events, call center activity, mail responses
This mapping is the raw material you’ll use to reconstruct journeys and measure how strategies interact across channels.
#3. No Data Silos
Data silos make it impossible to connect a user’s journey across channels, actively eroding trust inside organizations. When systems do not communicate, teams see:
- Conflicting performance reports
- Inaccurate ROI calculations
- Disagreement on what constitutes a real conversion
- Inability to track customers across devices and sessions
Common root causes include inconsistent identifiers, mismatched timestamps, weak CRM hygiene, and disconnected offline data.
The Technical End-to-End MTA Data Architecture
Once you acknowledge that data integration is the foundation, the architectural picture becomes clearer.
Basic MTA Data Architecture
At this stage, attribution is no longer dependent on any one platform’s internal reporting. It becomes reproducible, auditable, and wholly owned by your organization.
Foundational Data Integration Strategies for MTA
With the architecture in place, the next layer of maturity comes from how you collect, unify, and govern the data flowing into it. This is where most MTA implementations succeed or fail.
Strategic Data Collection Beyond Basic Pixels
Tracking pixels are table stakes, but they’re not enough for modern attribution. Mature MTA systems rely on server-first and API-driven collection strategies that are resilient to privacy changes and ad blockers.
This typically includes:
- Server-side tagging (e.g., GTM Server):
Reduces reliance on fragile client-side scripts, mitigates signal loss from ad blockers, and improves data durability as browser privacy tightens. - Consistent UTM governance:
Standardized naming conventions enforced across platforms to prevent source, medium, and campaign fragmentation. - API-based ingestion:
Direct data pulls from ad platforms, CRMs, and marketing tools, eliminating CSV exports and manual data handling.
Together, these approaches form the durable intake layer on which modern attribution depends. Some companies try to set this up themselves; others rely on MetricMaven to get the job done more quickly, more smoothly, and with complete compatibility and versatility tailored to their needs.
Harmonizing Disparate Data Sources
Raw data alone is not attribution-ready. Once ingested into the warehouse, it must be standardized and reconciled across systems, including:
- Standardizing timestamps (typically to your local timezone)
- Normalizing channels and sources into a clean taxonomy
- Resolving identity conflicts across devices, emails, and CRM IDs
- Deduplicating overlapping events and conversions
This transformation phase converts disconnected platform data into trustworthy analytical inputs for attribution modeling.
Architecting the Centralized Data Hub
The warehouse itself acts as the operational hub for all attribution logic. It:
- Stores all harmonized marketing and customer data
- Powers complex path, funnel, and cohort queries
- Supports MTA modeling without impacting production systems
Once this hub is in place, attribution becomes a true data product rather than a byproduct of ad-platform reporting.
Understanding Attribution Model Types (And When Each One Works Best)
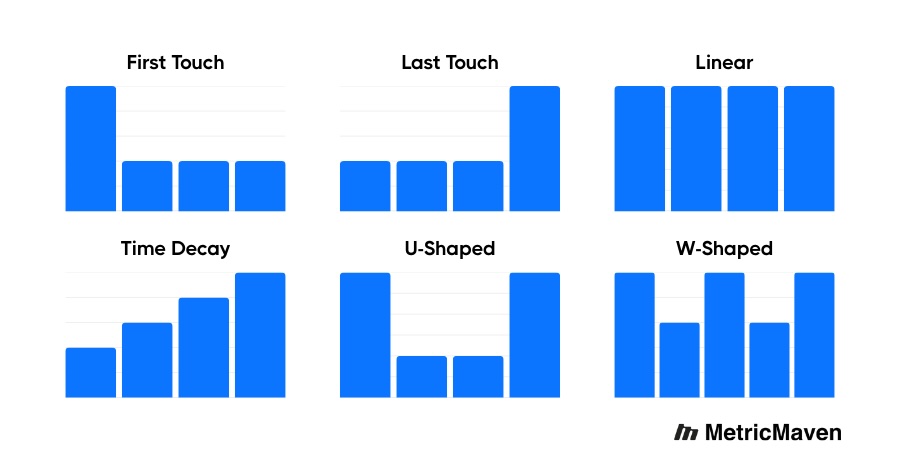
Once your data foundation is solid, attribution models finally become meaningful. A model is simply the logic used to distribute conversion credit across the customer journey. Each model answers a slightly different business question, and no single model is “universally best.” The right choice depends on your sales cycle length, funnel complexity, and optimization goals.
Below is a breakdown of the most common attribution models, what each one actually does, and when it’s most effective.
#1. First-Touch Attribution
What it does:
Assigns 100% of conversion credit to the very first interaction a user has with your brand.
Best for:
- Measuring top-of-funnel demand generation
- Evaluating brand awareness and acquisition campaigns
- Early-stage startups focused on customer discovery
Limitations:
Completely ignores everything that happens after initial discovery, making it unsuitable for optimization or revenue forecasting.
#2. Last-Touch Attribution
What it does:
Assigns 100% of conversion credit to the final interaction before conversion.
Best for:
- Bottom-of-funnel optimization
- Sales-driven organizations focused on conversion triggers
- Short sales cycles with minimal nurturing
Limitations:
Over-credits closing channels (like branded search or retargeting) and undervalues nurturing and awareness channels.
#3. Linear Attribution
What it does:
Distributes equal credit across every touchpoint in the journey.
Best for:
- Organizations seeking a balanced, non-biased baseline
- Early MTA adoption where advanced modeling isn’t yet ready
- Long, multi-channel nurture cycles
Limitations:
Assumes every interaction is equally influential, which isn’t realistic in most buying decisions.
#4. Time-Decay Attribution
What it does:
Assigns more weight to touchpoints closer to the conversion, with earlier interactions receiving progressively less credit.
Best for:
- Businesses with long sales cycles
- B2B funnels where late-stage nurturing strongly influences closing
- Subscription and SaaS products with extended evaluation periods
Limitations:
Still underestimates early awareness and demand creation.
#5. U-Shaped Attribution
What it does:
Heavily weights the first interaction and the conversion interaction, with the remaining credit spread across mid-funnel touches.
Best for:
- Lead-generation funnels
- Marketing teams optimizing acquisition + conversion efficiency
- Companies with a clear handoff between marketing and sales
Limitations:
Mid-funnel nurturing still tends to be underweighted.
#6. W-Shaped Attribution
What it does:
Emphasizes three key milestones:
- First interaction (awareness)
- Lead creation
- Opportunity creation
The remaining credit is distributed across supporting touches.
Best for:
- B2B sales organizations
- Revenue teams modeling the full marketing-to-sales pipeline
- CRM-driven funnels with clear lifecycle stages
Limitations:
Requires clean CRM stage data to function correctly.
#7. Full-Path Attribution
What it does:
Extends W-shaped logic across the entire lifecycle, weighting multiple predefined milestones from first touch through deal close.
Best for:
- Enterprise RevOps environments
- Multi-stakeholder buying journeys
- Complex account-based marketing (ABM) programs
Limitations:
Requires advanced data engineering, lifecycle governance, and identity stitching.
#8. Data-Driven Attribution
What it does:
Uses historical conversion path probability to calculate the true incremental contribution of each touchpoint.
Best for:
- High-volume conversion environments
- Mature data warehouses with clean, unified event streams
- Organizations optimizing budget allocation at scale
Limitations:
Computationally intensive and only as accurate as the underlying data quality.
#9 Machine-Learning-Based Attribution
What it does:
Uses machine learning models trained on your unique customer behavior to adaptively assign credit based on real performance patterns.
Best for:
- Enterprises with large datasets
- Dynamic media mix environments
- Predictive optimization and automated budget shifting
Limitations:
Requires robust MLOps, model monitoring, and governance to avoid bias and drift.
TL;DR: Which Attribution Model Is Best for Your Data?
There is no single “best” attribution model, as the right one depends entirely on your data maturity, sales cycle length, and the cleanliness of your identity and CRM signals.
If your data is basic or fragmented → Start with Last-Touch or Linear
If you run lead-gen or B2B funnels → Use U-Shaped or W-Shaped
If you have a mature warehouse + strong CRM hygiene → Move into Full-Path or Data-Driven
If you operate at enterprise scale with unified first-party data → Machine-Learning models unlock the most value
If you’re unsure which model your current data can actually support, or you want to validate that your attribution isn’t misleading your budget decisions, MetricMaven can audit your stack and recommend the right model based on your real infrastructure, not theory.
Talk to MetricMaven to align your data to the right attribution strategy.
An Engineering View of MTA Data Pipeline Stages
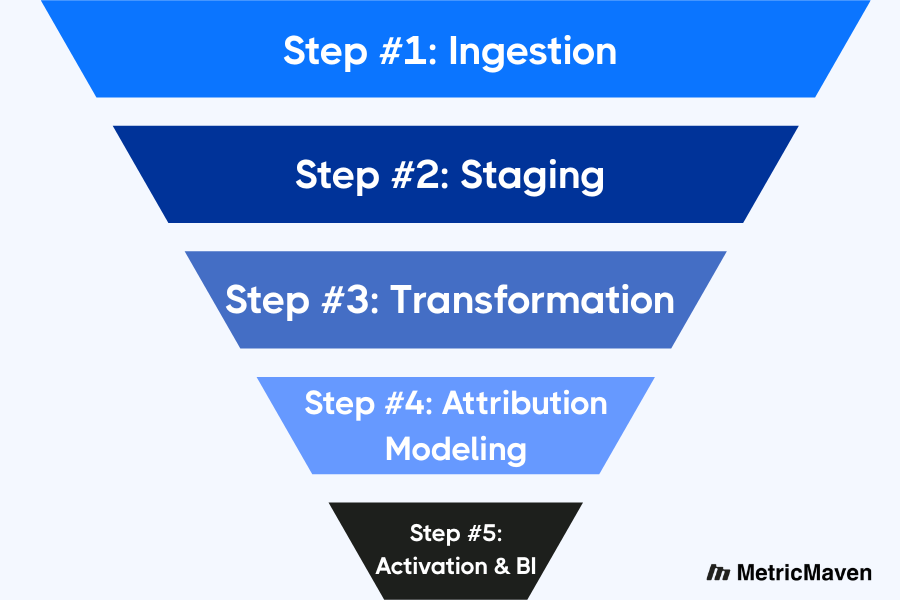
Attribution does not happen inside a dashboard. It is the output of a carefully engineered data pipeline that moves information from fragmented platforms into a unified analytical system. When that pipeline breaks, attribution breaks with it.
At a high level, every production-grade MTA system follows the same lifecycle:
Source → Ingestion → Staging → Transformation → Modeling → Activation
Each layer exists to solve a specific failure mode in attribution. Skipping or oversimplifying any stage introduces blind spots that compound downstream.
Step #1: Ingestion
How data enters the system
This is the collection layer where raw events first leave external platforms and enter your ownership. In mature stacks, ingestion typically combines:
- APIs from Google Ads, Meta, LinkedIn, sales platforms, and CRMs
- Webhooks for near-real-time behavioral signals
- Server-side tagging via GTM Server or custom collectors
This replaces fragile browser-only tracking with controlled, first-party data capture that survives ad blocking, cookie loss, and changes to browser privacy settings.
Step #2: Staging
Preserving raw truth
Once ingested, raw data must be stored unchanged before any modeling begins. These tables act as your audit layer and historical system of record. Staging tables typically:
- Preserve platform-native schemas
- Retain unaltered timestamps and identifiers
- Allow full replay of history if logic changes
This is what makes attribution reproducible and defensible months or years later.
Step #3: Transformation
Where attribution happens
Transformation is where raw feeds become analytical truth. This is the most critical engineering layer in the entire MTA stack. Using tools like dbt or native SQL pipelines, transformation handles:
- Event deduplication across overlapping platforms
- Sessionization (grouping events into coherent visits)
- Identity stitching across anonymous and known behavior
- Channel normalization (clean source/medium/campaign taxonomy)
This is where fragmented marketing activity becomes a coherent customer journey.
Step #4: Attribution Modeling
Applying logic
Only after transformation is stable can attribution logic be trusted. At this stage, rule-based, probabilistic, or machine-learning models are applied to fully stitched journeys. This separation is critical. Modeling should change frequently, data infrastructure should not. If models and transformations blur together, attribution becomes volatile and untrustworthy.
Step #5: Activation & BI (The Final Layer)
Turning insights into action
The final layer makes attribution operational. Clean modeling outputs are pushed into:
- BI tools (Looker, Power BI, Tableau, Looker Studio)
- Ad platforms for smart bidding and budget reallocation
- CRMs for lead scoring and sales prioritization
- Executive dashboards for revenue reporting
This is what closes the loop between measurement, optimization, and growth.
Identity, Server-Side Tracking, and First-Party Data
Everything above depends on your ability to recognize the same person or account across tools and over time.
Identity Resolution
Without robust identity resolution, your models are just educated guesses. Strong MTA setups combine:
- Login-based IDs (user/account IDs from auth systems)
- CRM identifiers (email, phone, CRM contact IDs)
- Hashed identifiers for privacy-safe joins with ad platforms
- Probabilistic signals (device, behavior, geo) when deterministic IDs are missing
Example: A user clicks a LinkedIn ad at work, signs up with their email later at home, and finally purchases after a sales demo. Login ID + CRM email + hashed email matching allow all three actions to be recognized as one continuous journey instead of three separate users.
Server-Side Tracking & Privacy-First Design
As third-party cookies fade and browser restrictions grow, client-side-only tracking is too fragile to anchor attribution. A server-side, privacy-first approach allows you to maintain reliable conversion tracking despite ad blockers.
Example: A Safari user with an ad blocker submits a lead form. The form event is sent server-to-server to Google Ads and Meta via CAPI, so the conversion is still attributed even though all browser pixels were blocked.
First-Party Data
First-party data is the information you collect directly from your customers, such as website logins, email opens, account activity, and it’s what makes modern multi-touch attribution reliable.
Example: A user clicks an email, visits your site, books a demo, and later closes with sales. When those signals are all captured as first-party data and tied to one identity, MTA can accurately credit every step.
Real-Time vs Batch Attribution: How Fast Do You Really Need It?
Not every organization needs real-time attribution. Over-building here is a common (and expensive) mistake.
Most teams end up with a hybrid mix: using batch for strategy and selective real-time for automation.
How to Keep MTA Trustworthy: Governance, QA, and Failure Modes
Even the best-built MTA stack will decay without governance. High-trust systems invest in:
- Data dictionaries so “conversion,” “lead,” and “opportunity” mean the same thing across teams
- Schema and event versioning so changes don’t silently break models
- Consent and privacy flag propagation through every step of the stack
- Identity audit logs to understand how and why IDs were merged
- Re-run capability so you can reproduce attribution for any period
- An expert team that makes sure everything runs smoothly, consistently, and without added overhead– like Metric Maven
If you’re going to manage this yourself, look out for these common failure modes:
- Cross-domain tracking quietly breaking
- Timezone mismatches between tools
- Poor CRM hygiene (duplicates, incomplete records)
- Inconsistent UTM naming
- Ad platforms overwriting attribution with their own last-click logic
The earlier you catch these, the more trust you preserve in your numbers (and in your team).
The Future of Attribution And How to Maximize Its Benefits Now
Multi-touch attribution is rapidly moving toward privacy-first measurement, server-side tracking, and AI-assisted modeling. As third-party cookies disappear and platforms restrict data access, reliable attribution will depend almost entirely on first-party data, unified identity, and durable data pipelines. The companies investing in these foundations now will be the ones that still have trustworthy performance visibility five years from today.
If you’re ready to make MTA work for you, but you’re not sure where/how/when to start, a partner like MetricMaven can audit your stack, validate your data, and design an attribution framework your leadership and engineers can stand behind.
Talk to us, we’re here to make sure you succeed with the insights you need.


Subscribe to our newsletter



Marketing analytics infrastructure for agencies. Server-side tracking, custom dashboards, and advanced analytics to improve marketing performance.